
So…you left your job and went traveling throughout Asia for 4 months. In small cyber cafe, somewhere in south Pakistan, you created WordPress site because you were lazy to send emails to friends and family. Internets loved you and your pictures were on the front page of Reddit many many times. Who could forget that great article about food poisoning in China or that unfortunate misunderstanding with gentleman in Bangkok…
When you got back everyone was like – “You should write a book!” and you said to yourself – “Why not… Half of the book is already written.”. This brings us to the subject of this post – importing WordPress site as a Booktype book.
Importing
There are couple of ways you can do it (this can be applied to other systems also):
- Use some kind of API to remotely access data. For this you only need permission to access data.
- Write your own plugin to export data from WordPress. Besides knowing how to write plugin you need permissions to install it on the remote server. You can use WordPress API to render the articles properly, something you can’t really do with other 2 methods.
- Finally the method we are using in this post. Parsing XML export file created with WordPress export plugin.
Importing data can be complex process and each method has its good and bad points. You probably don’t want to have chapter for each post in WordPress because that could be hundred and hundred of chapters at the end. Maybe you want to choose which chapters you want and sometimes to combine couple of posts as one chapter. These are just some of the issues.
How it works

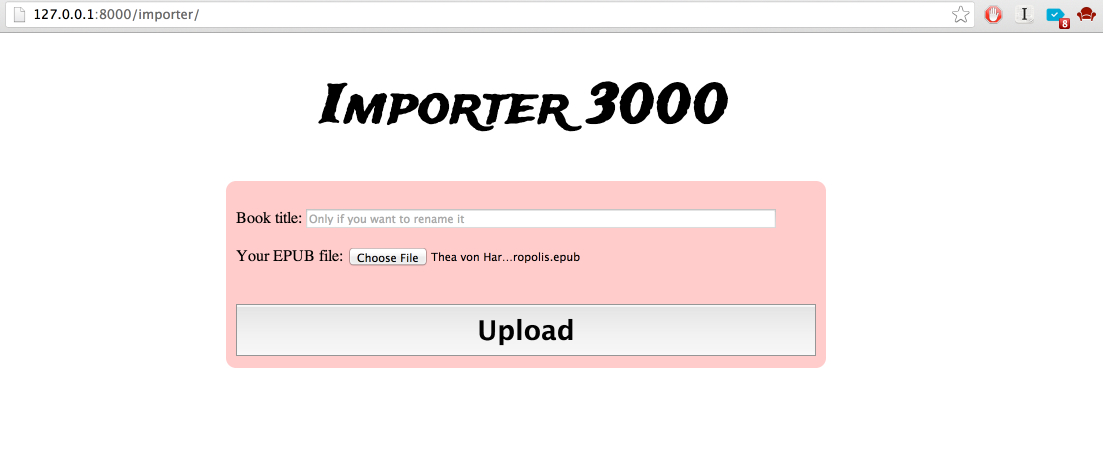
As it is visible on the picture above you should go to Tools/Export and choose what you want to export. Download the “Export File” to you computer. Export file is just extended RSS file and you can (and should) use it to export content of your site. Notice that attachments and images are not part of this export file, we will need to download them separately! Besides content is in “raw” format (before everything was rendered to HTML).
Like I said, export file is extended RSS file and for parsing we use this great library feedparser. Book name can be specified with arguments but for the default name we use title of the WordPress site. Booktype cares about two titles. One is the full title of the book and the other one is unique url name of the book (usually slugified version of full title).
from booki.utils.book import createBook
book = createBook(conf['user'],
conf['bookTitle'],
status = 'new',
bookURL=conf['bookTitleURL'])
As you can see we use function createBook. It takes user object as first argument (someone has to be owner of the book), full book title, default book status (books can have different statuses) and slugified title name. Export file provides us with the information about WordPress administrator and Post author. We could use that information to find or create Booktype user with specific info and set that person as Book owner.
Parsing posts
After this we just go through the list of all the posts in export file and ignore those who don’t have ‘wp_status’ set ‘publish’. Like i said, content of that chapter is in “raw” format. For instance empty lines in text are representing start of new chapter and etc. If we were using specific tags to format our code (for instance, to prettify the source code) we would not get nice and colorful HTML.
In this example we just do two modifications. One is to create paragraphs in text and the 2nd one is to put Chapter title inside of H2 tag. That is one of the Booktype requirements at the moment.
content = "\n".join(["< p >%s< /p >" % p for p in content.split('\n\n') if p.strip() != ''])
content = u'< h2 >%s< /h2 >%s' % (chapterTitle, content)
And yes… I have some extra spaces in tags P and H2 because i am too lazy to figure out how to escape it in code prettifier plus the code to make paragraphs is not perfect (but this is just an example).
Images
Now we parse Post content and search for the images. When we find one, we try to download it to our computer. Normally we wouldn’t need to do it, but Booktype really wants to have entire content of a book locally. When the image is successfully downloaded we save it as an attachment and we modify image location. All images must be placed inside of ‘static/’ directory. There are good reasons why it has to be relative path, but we will not talk about it now.
att = models.Attachment(book = book,
version = book.version,
status = stat)
f2 = File(StringIO(data))
f2.size = len(data)
att.attachment.save(fileName, f2, save=True)
fileName = os.path.basename(att.attachment.path)
e.set('src', 'static/%s' % fileName)
Chapter
At the end we just create new Chapter. This is very basic way of creating new chapter because we are not leaving any traces in our logs and etc… We can leave that for some other example. Also notice we are not doing anything with links to other posts/chapters on the same site/book. We just ignore that for now.
chapter = models.Chapter(book = book,
version = book.version,
url_title = bookiSlugify(chapterTitle),
title = chapterTitle,
status = stat,
content = content,
created = now,
modified = now)
chapter.save()
Source
Look at the full source for WordPress importer in my Booktype Scrolls repository. Purpose of this code is to be more educational and less production ready.
As you can see technical part of importer is very simple. Thumblr has API for remote access and it would be fairly simple task to make Thumblr importer (or for any other CMS). The biggest problem is still how to make their HTML work nicely inside of Booktype. If author is using custom CSS on WordPress side then Booktype would be completely unaware of it. For instance – <img class=”alignnone size-full wp-image-591″ … It would be the same for different WordPress plugins, broken HTML, headings at wrong place, JavaScript plugins and etc.














{kind=link}